Reinforcement Learning as a fine-tuning paradigm

Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.

Reinforcement Learning Pretraining for Reinforcement Learning

Fine-Tuning Language Models Using Direct Preference Optimization

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds, by Enes Bilgin, RL Agent

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds
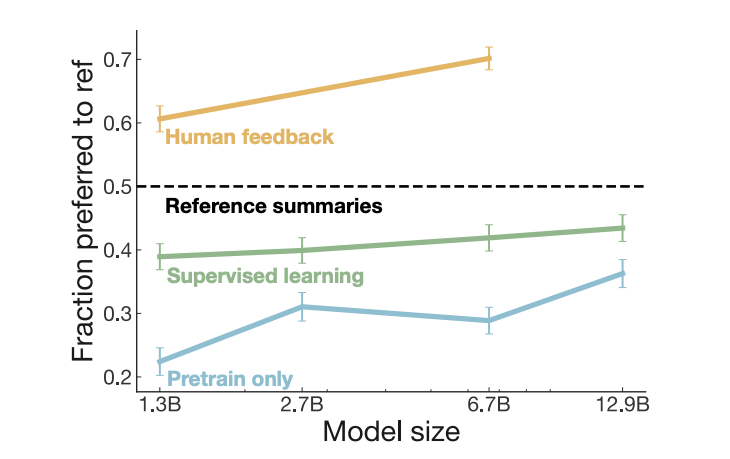
Reinforcement Learning as a fine-tuning paradigm
Computers, Free Full-Text

D] Reinforcement Learning As A Fine-Tuning Paradigm : r/MachineLearning
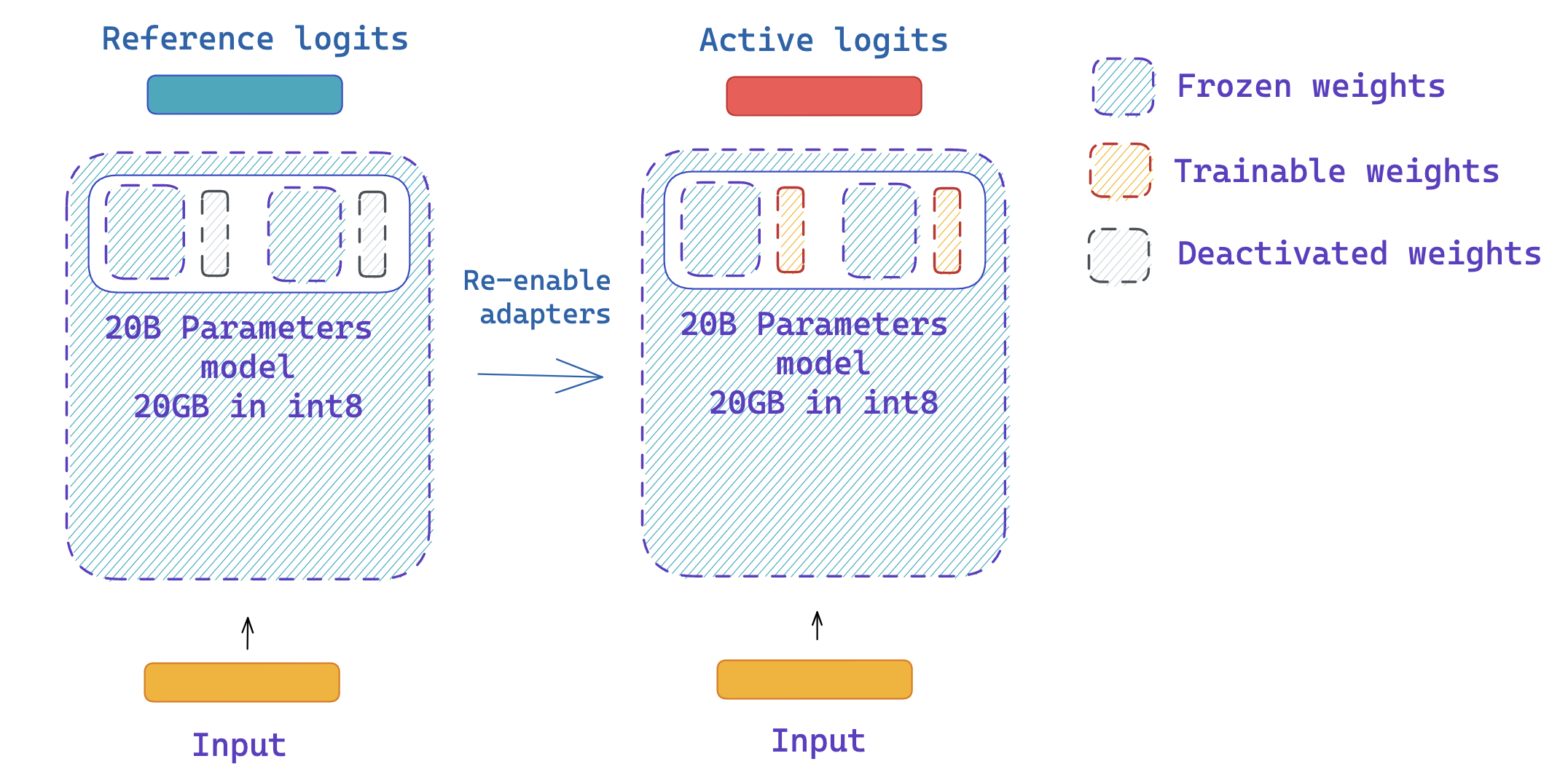
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

The AiEdge+: How to fine-tune Large Language Models with Intermediary models
Introducing Transfer Learning as Your Next Engine to Drive Future




:max_bytes(150000):strip_icc():focal(749x164:751x166)/kim-kardashian-skims-crash-012324-tout-d76e32c08c8a40cebcc556ab6001821e.jpg)
