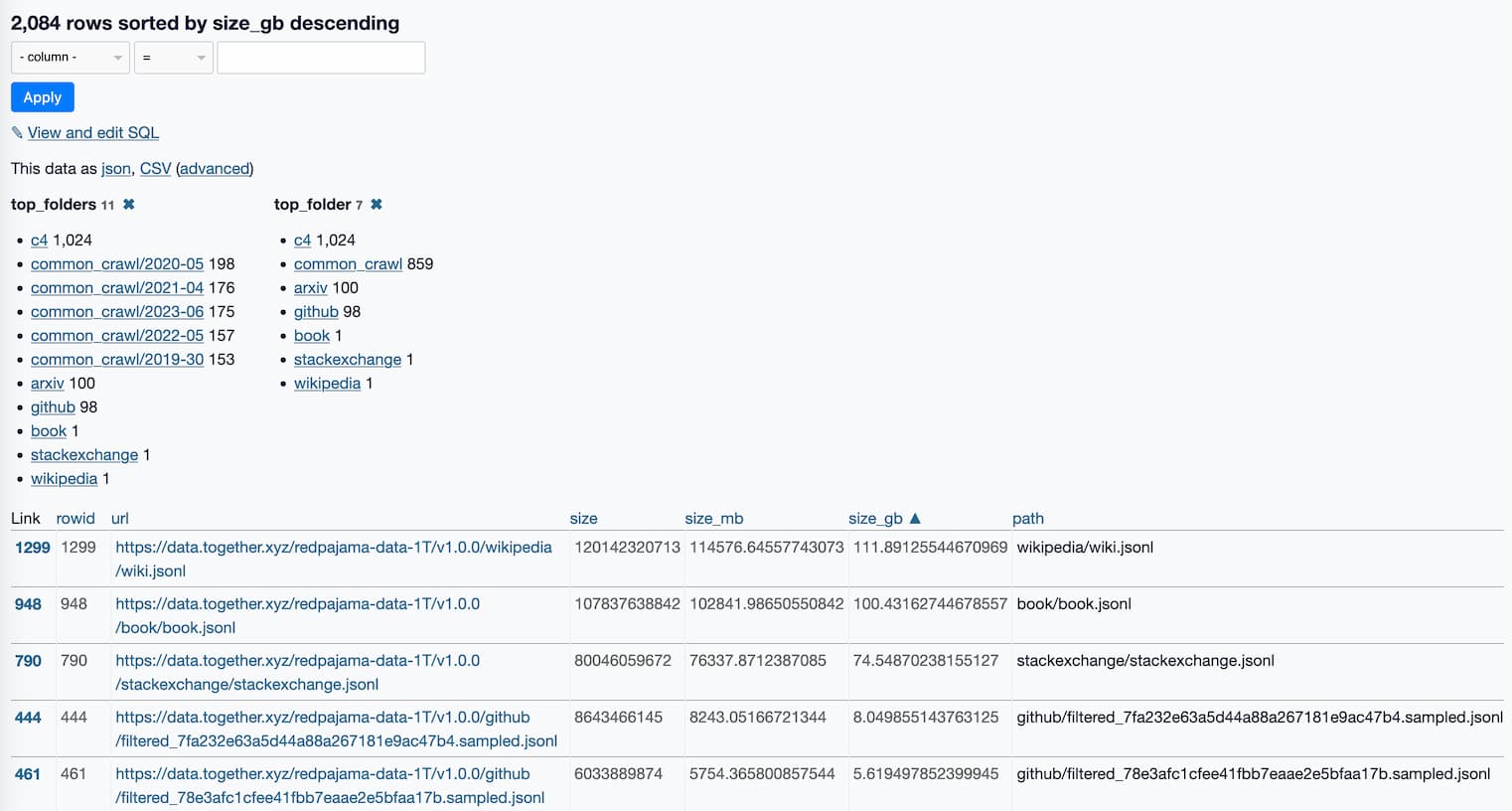
What's in the RedPajama-Data-1T LLM training set
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, …
RedPajama Project: An Open-Source Initiative to Democratizing LLMs

RedPajama 7B now available, instruct model outperforms all open
Web LLM runs the vicuna-7b Large Language Model entirely in your

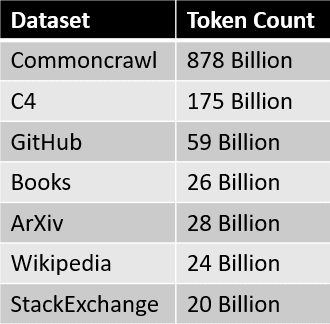
Open-Sourced Training Datasets for Large Language Models (LLMs)
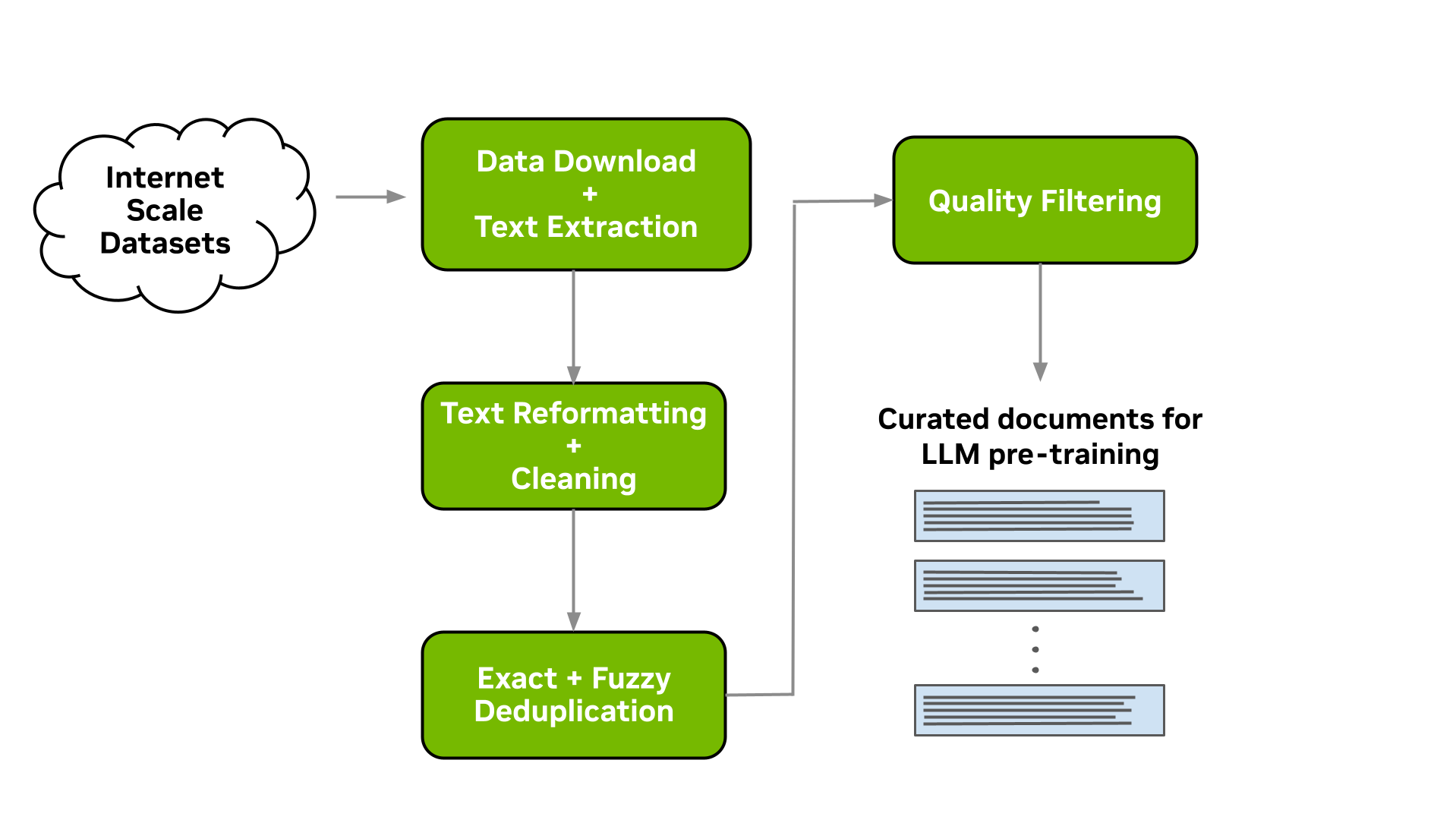
Curating Trillion-Token Datasets: Introducing NVIDIA NeMo Data

Together AI Releases RedPajama v2: An Open Dataset with 30

Training on the rephrased test set is all you need: 13B models can
Web LLM runs the vicuna-7b Large Language Model entirely in your

RedPajama-Data-v2: An open dataset with 30 trillion tokens for

65-Billion-Parameter Large Model Pretraining Accelerated by 38







