Stable Video Diffusion — Convert Text and Images to Videos, by Shrinivasan Sankar
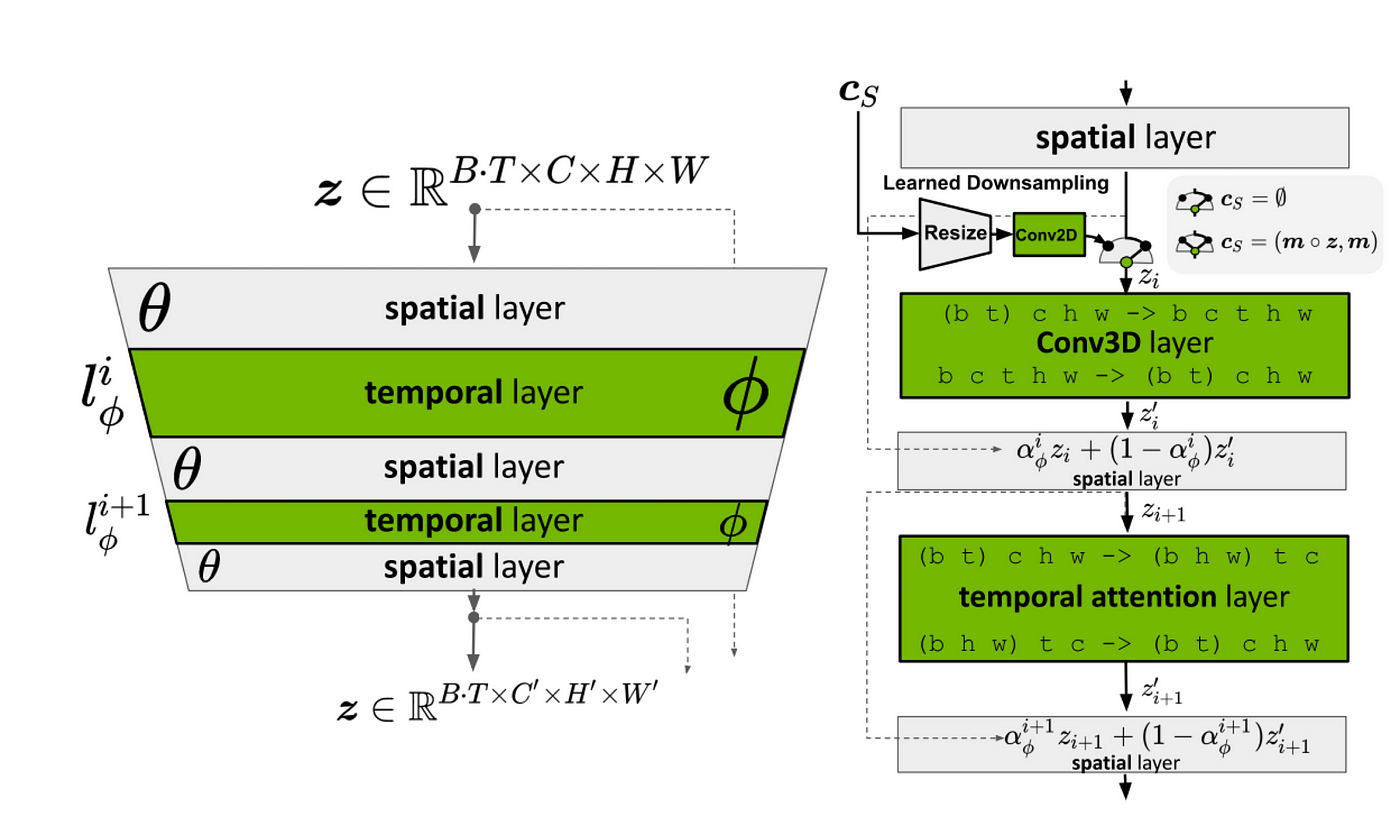
Diving deeper into the Stable Video Diffusion model, its architecture, the proposed Large Video Dataset, and the results Stability AI, one of the leading players in the image generation space, has…

Google Unveils Its Most Promising Text-to-Video Model Yet: Lumiere

Shrinivasan Sankar - AI Bites
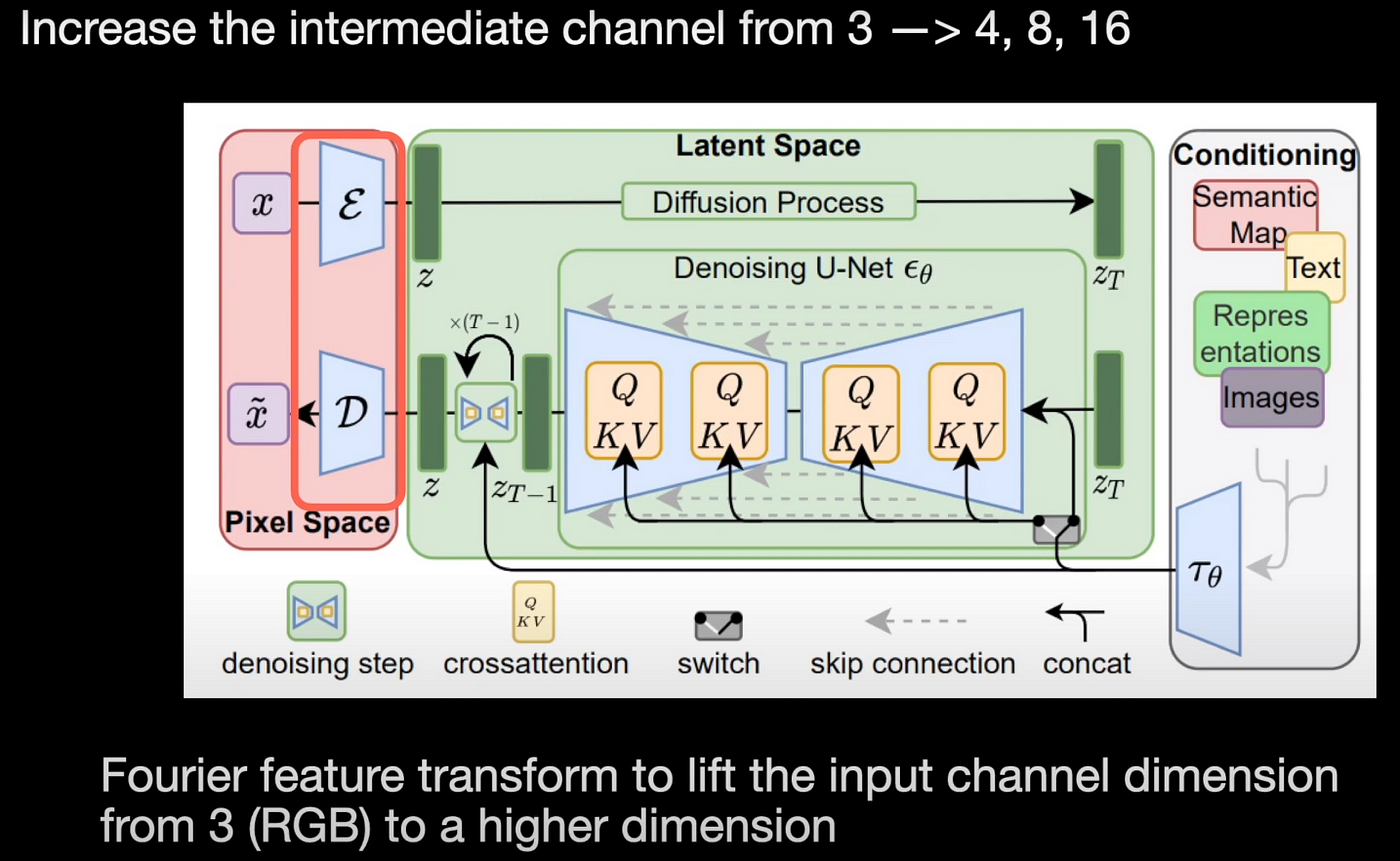
Emu — the foundation model for Emu Edit and Emu Video, by Shrinivasan Sankar

Video Clasification PDF, PDF, Deep Learning
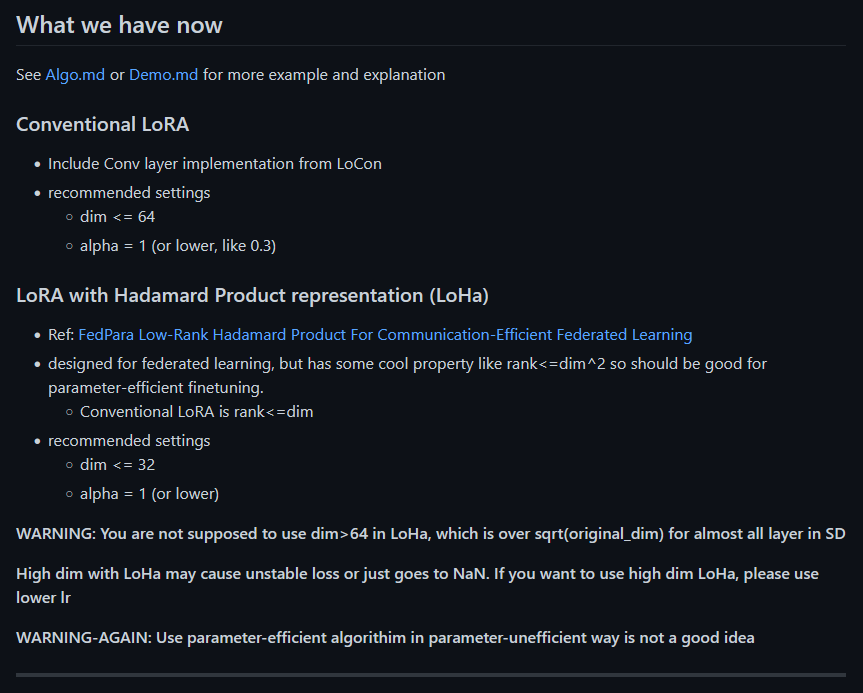
Alpha and Dimensions: Two Wild Settings of Training LoRA in Stable Diffusion, by Ashe Junius

Strategic Applications Agenda for selected Key Areas - eMobility CA

Alpha and Dimensions: Two Wild Settings of Training LoRA in Stable Diffusion, by Ashe Junius

Shrinivasan Sankar on LinkedIn: Positional Encoding and Input Embedding in Transformers - Part 3
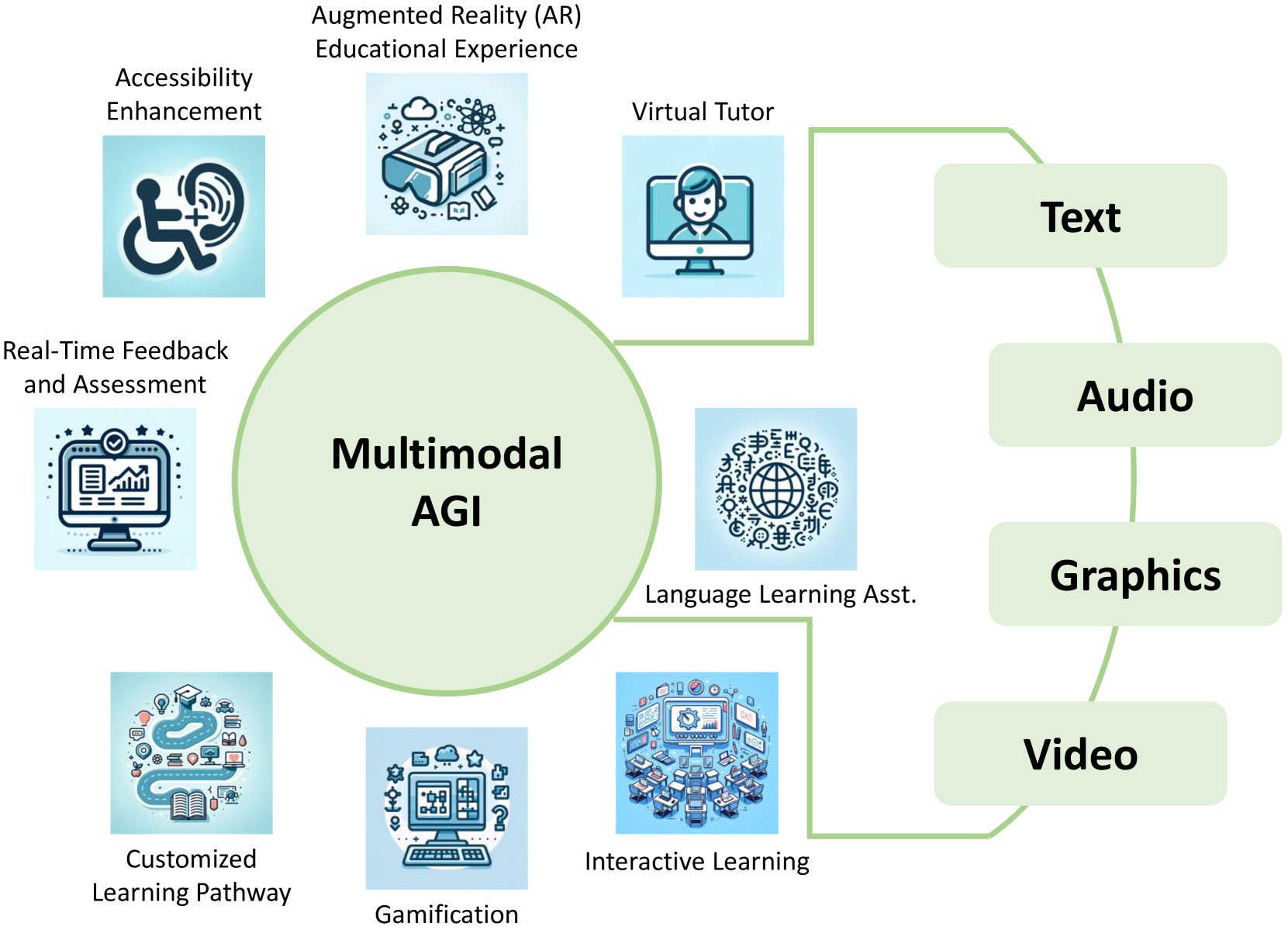
Multimodality of AI for Education: Towards Artificial General Intelligence

Parameter Efficient Fine-tuning of the Gemma model on a single GPU, by Shrinivasan Sankar, Mar, 2024
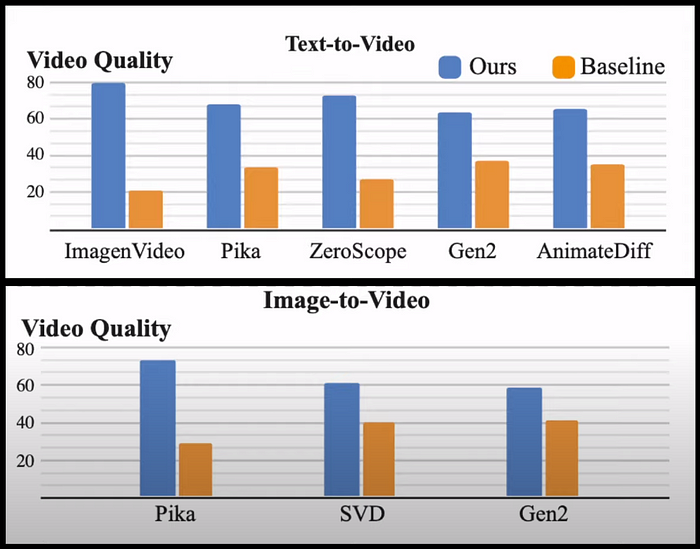
Google Unveils Its Most Promising Text-to-Video Model Yet: Lumiere
GitHub - zhtjtcz/Mine-Arxiv







