Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Optimizing Apache Spark Performance: Tackling Data Skew for Faster Big Data Processing, by VivekR
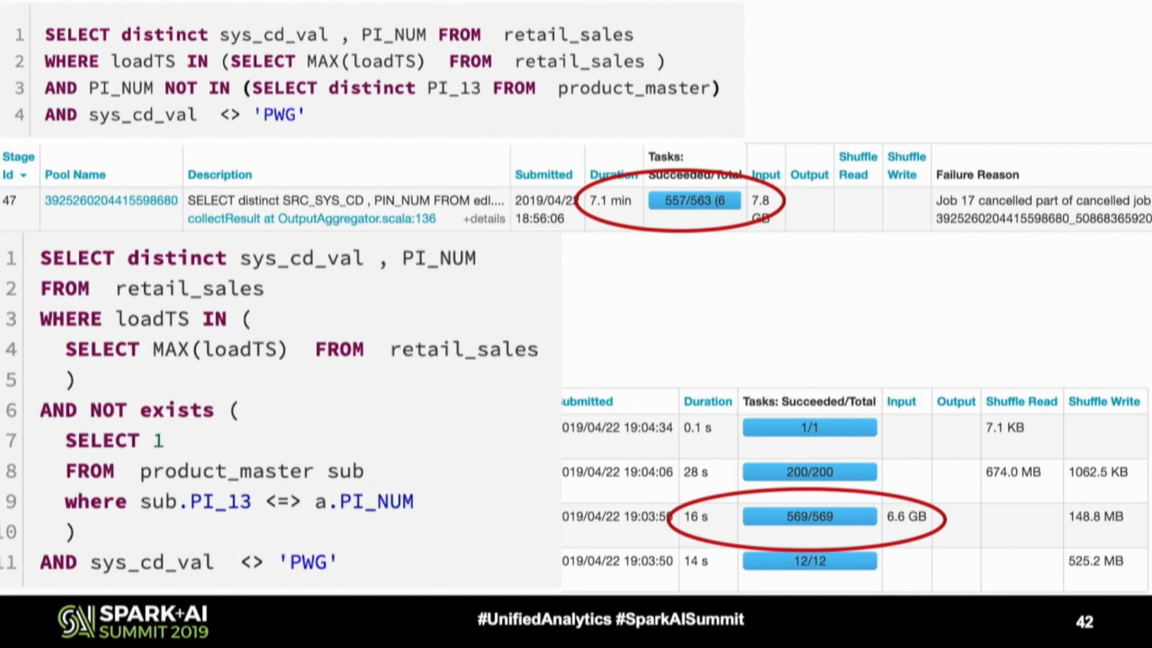
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark

Azarudeen S on LinkedIn: #spark #apachespark #spark #optimization #interviewpreparation
Databricks Notebook Promotion using Azure DevOps, by Himansu Sekhar, road to data engineering

Cranking the Voltage on Spark: Achieve Peak Performance with Optimization, by BlackRockEngineering
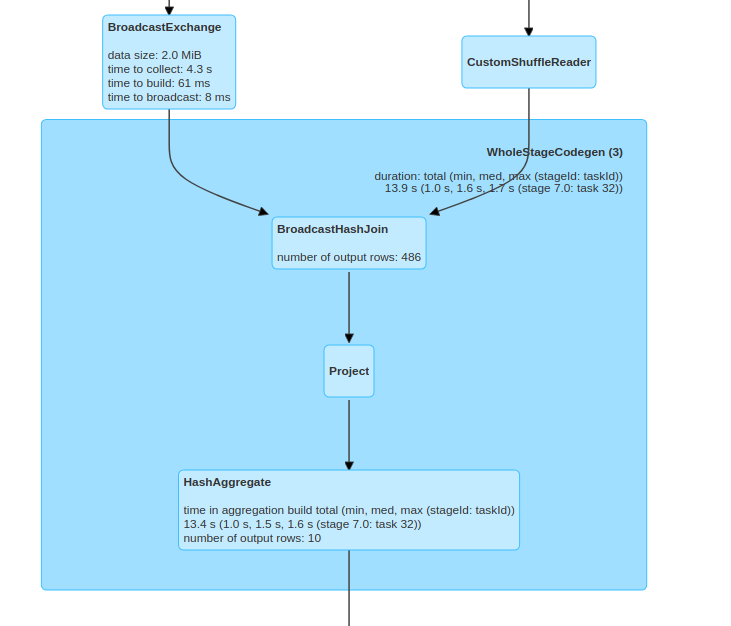
Spark 3.0: First hands-on approach with Adaptive Query Execution (Part 2)

Data engineering and intelligent computing : proceedings of IC3T 2016 978-981-10-3223-3, 9811032238, 978-981-10-3222-6

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering

Spark Performance Tuning: Skewness Part 2, by Wasurat Soontronchai

Business Intelligence Career Master Plan Launch, PDF, Business Intelligence

Kiran Sreekumar on LinkedIn: #databricks #spark #performanceoptimization

Principles of Data Science [1st ed.] 9783030439804, 9783030439811

PDF) Proceedings of 3rd International Conference on Emerging Technologies in Computer Science & Engineering ICETCSE 2016
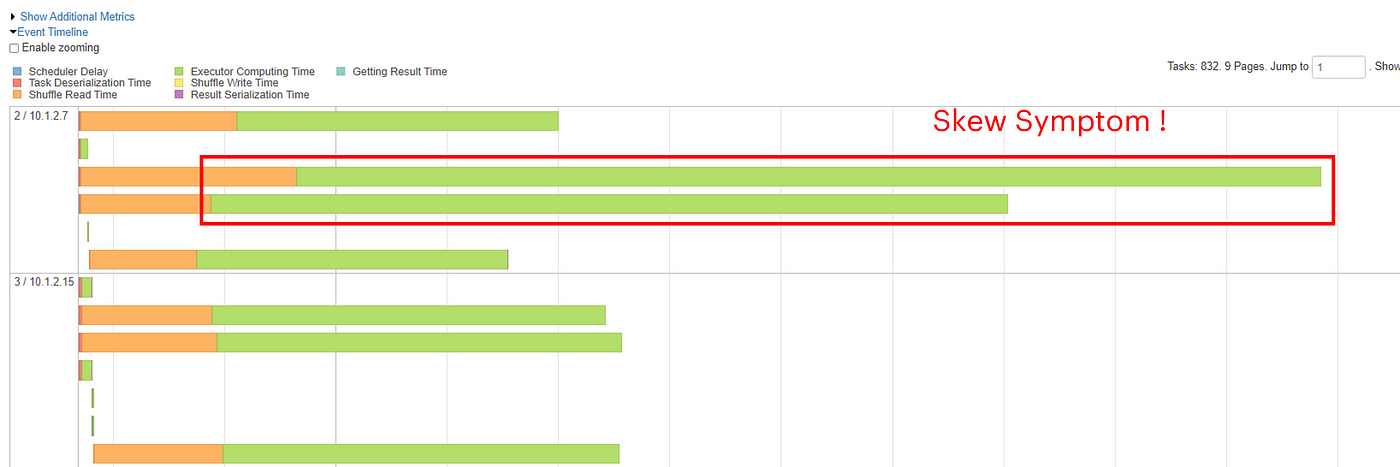
Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai







