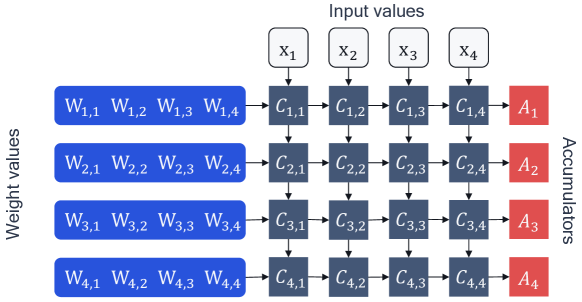
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
By A Mystery Man Writer

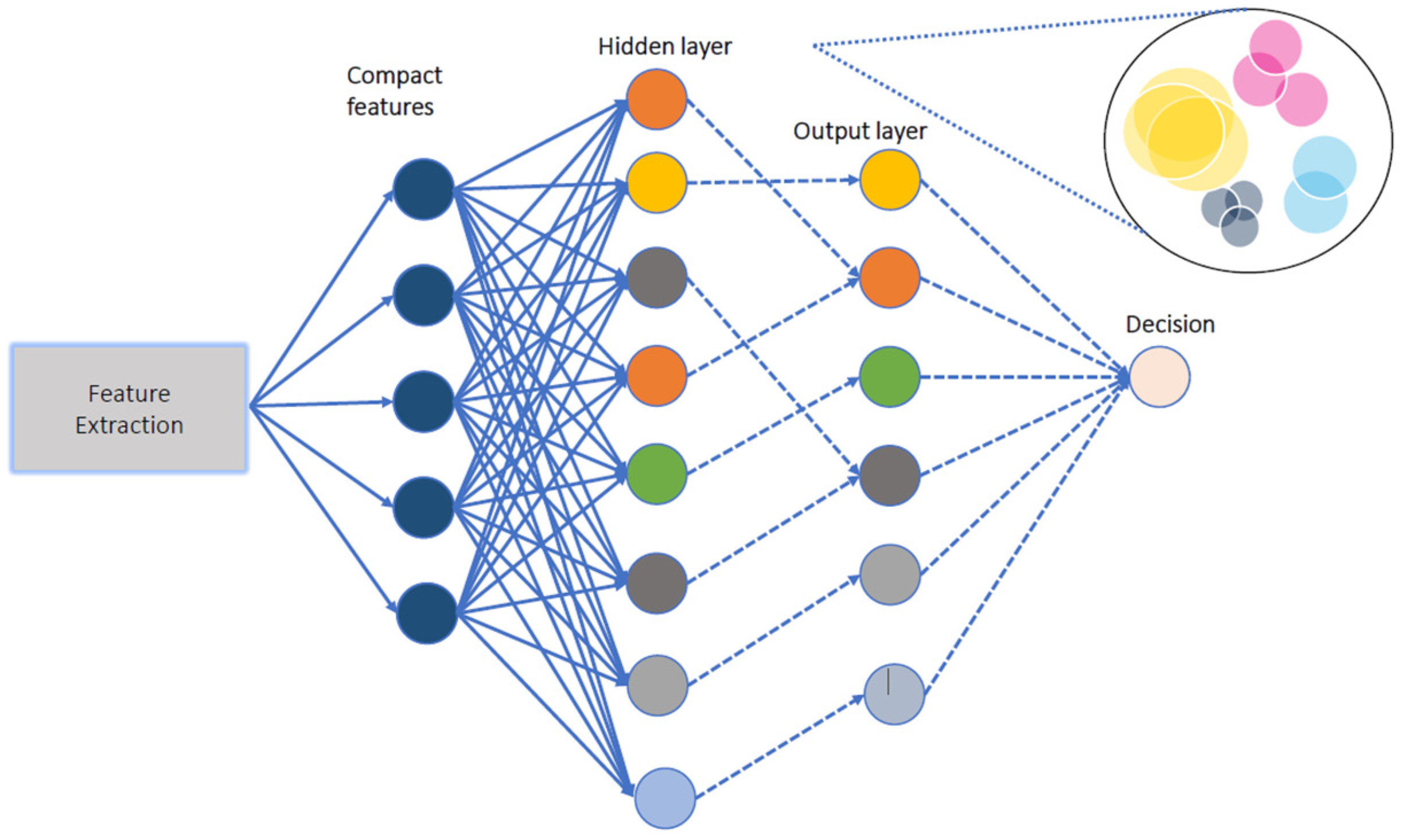
Machine Learning Systems - 10 Model Optimizations

Ps and Qs: Quantization-aware pruning for efficient low latency neural network inference

Quantized Training with Deep Networks, by Cameron R. Wolfe, Ph.D.

Accuracy of ResNet-50 quantized to 2 and 4 bits, respectively.
2106.08295] A White Paper on Neural Network Quantization
Chips, Free Full-Text

Visualization of the loss surface as a function of quantization ranges

Sensors, Free Full-Text

Network Pruning




:format(webp)/https://static-my.zacdn.com/p/modernform-international-3517-0895461-1.jpg)


