BERT-Large: Prune Once for DistilBERT Inference Performance

Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.
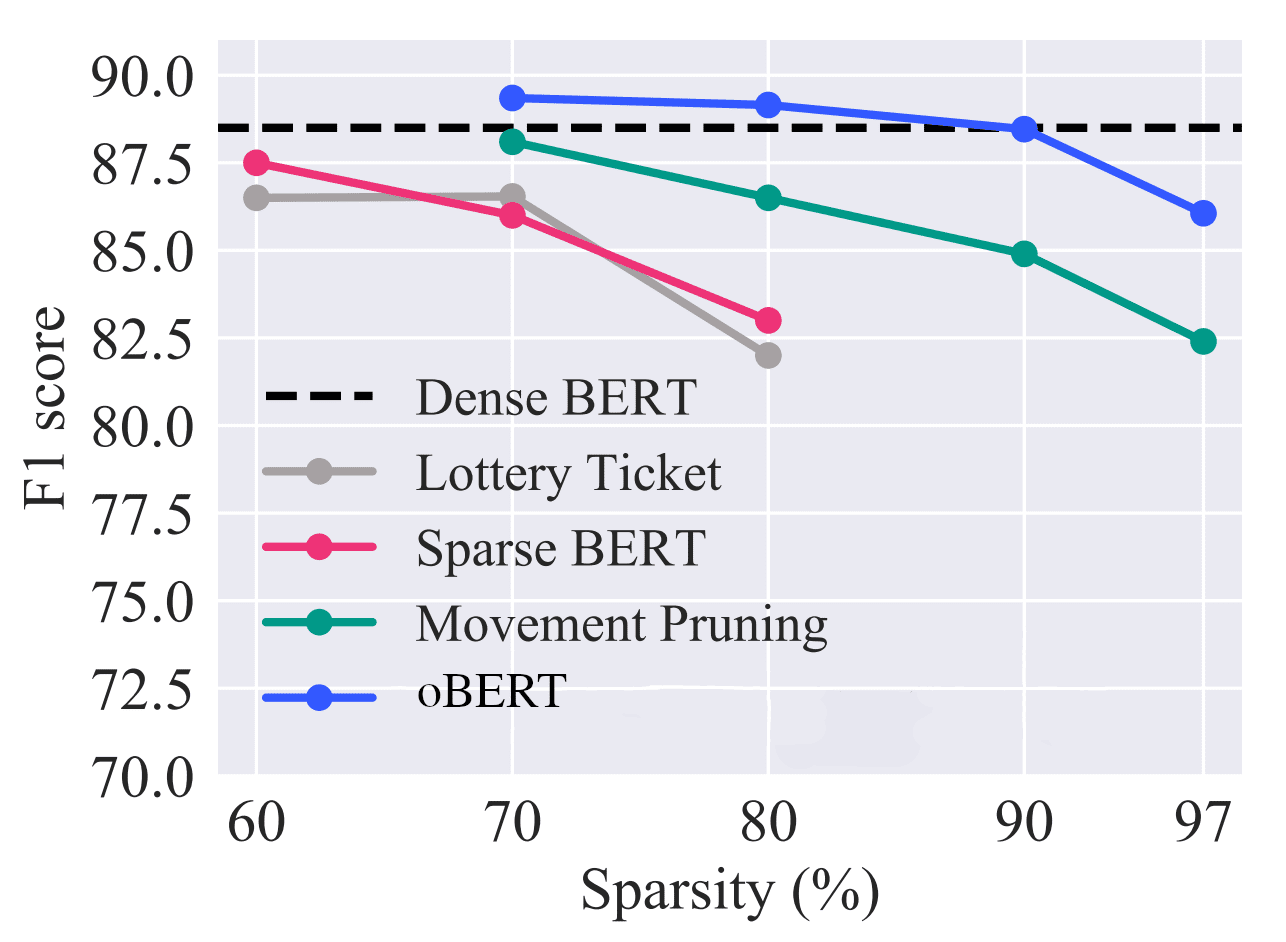
oBERT: Compound Sparsification Delivers Faster Accurate Models for NLP - KDnuggets

🏎 Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT, by Victor Sanh, HuggingFace

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Understanding Distil BERT In Depth, by Arun Mohan

Mark Kurtz on LinkedIn: BERT-Large: Prune Once for DistilBERT

Distillation of BERT-Like Models: The Theory

Model Compression and Efficient Inference for Large Language Models: A Survey
BERT-Large: Prune Once for DistilBERT Inference Performance

Tommy Gunawan on LinkedIn: Probabilistic Model

Distillation of BERT-Like Models: The Theory

Large Language Models: DistilBERT — Smaller, Faster, Cheaper and Lighter, by Vyacheslav Efimov
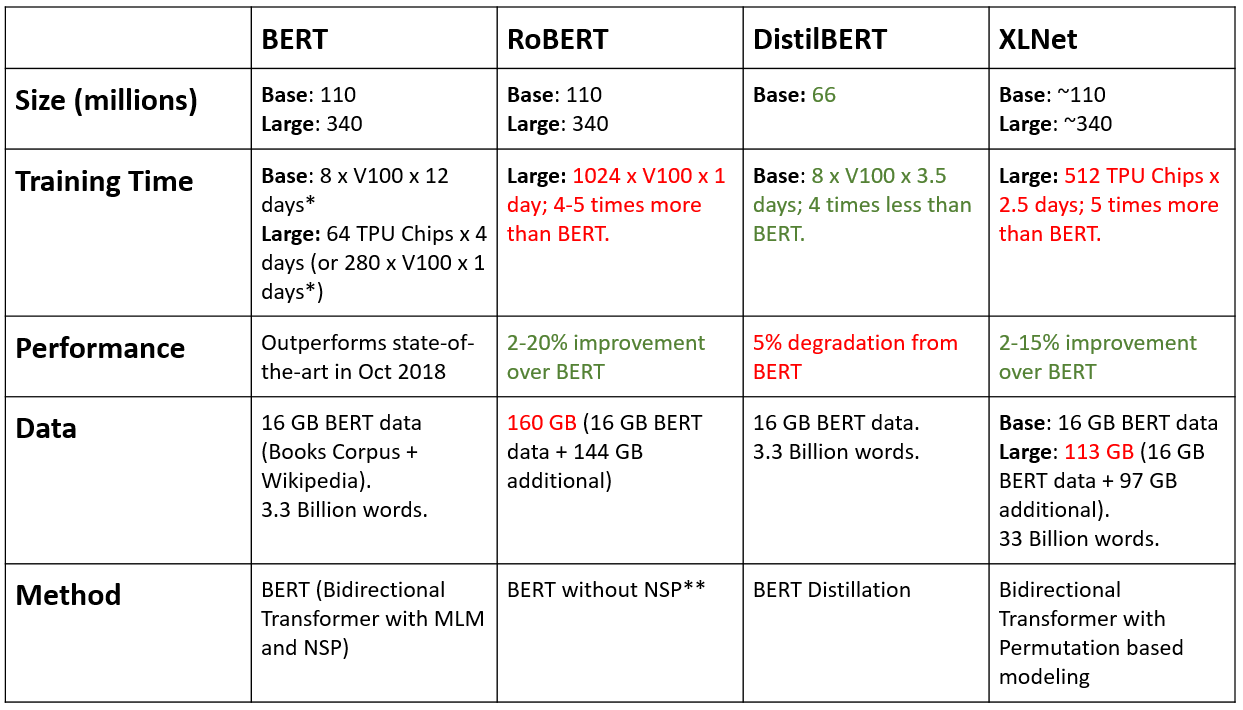
BERT, RoBERTa, DistilBERT, XLNet: Which one to use? - KDnuggets







